Here’s a high-confidence prediction for 2024 – lawsuits against AI companies will make it a banner year for lawyers. With potential monetary damages measured in billions of dollars, the loudest boom will be from the NYTimes copyright lawsuit filed against OpenAI and Microsoft. This boom will reverberate across the Big Tech – Media landscape and spawn two more predictions. First, the NYTimes and other large publishers have leverage and will do well in these cases. And second, Big Tech will gladly settle and still thrive, as always.
In this post we will: 1) provide some relevant industry context, 2) summarize the Microsoft lawsuit, 3) review custom dialogs we created using ChatGPT 4.0 and Microsoft Copilot (AKA Bing-Chat) with a use-case based on NewsGuard data, 4) analyze and verify prompt results using DomainTools and traditional search methods, and 5) review why we believe that the publishers have the most leverage. Our findings support one of the key assertions in the Microsoft case: Chatbots propensity to hallucinate poses reputational risk to publishers.
Context: While our primary focus is on the NYTimes lawsuit against OpenAI and Microsoft [1, 2], the analysis must be understood in the context of other relevant events involving content publishers and Generative AI companies. For example:
- Other lawsuits: We identified ten lawsuits using a combination of direct Google Search and ChatGPT and Copilot assisted search. These lawsuits against generative AI companies encompass a range of case types including copyright infringement, trademark, privacy class action, facial recognition, and defamation tort cases. [1-7]
- Terms of Service Restrictions: The NYTimes, Reddit and X are among the companies that have changed their Terms of Service to limit web scraping and API access by Chatbot LMM (Large Language Model) crawlers. [3]
- Licensing Deals: The Associated Press and Axel Springer (publisher of Politico and Business Insider) have concluded large licensing deals with OpenAI. The Springer deal is reported to be performance based with annual revenues ~ $10M. [8]
- Negotiations: Apple is in negotiations for large licensing deals ($50M) with news and publishing organizations including Condé Nast (Vogue and The New Yorker), NBC News, People Magazine, The Daily Beast and Better Homes. [9] This will create pressure on other LMM providers to negotiate deals and strengthen the leverage of publishers.
NYTimes Lawsuit: In its 69-page filing in the U.S. DISTRICT COURT SOUTHERN DISTRICT OF NEW YORK, the NYTimes accuses OpenAI and Microsoft of ‘free-riding’ and infringing on millions of NYTimes copyrighted documents in order to train their chatbots. [2] Notable claims in the suit:
- Defendants should be held responsible for “billions of dollars in statutory and actual damages”. While the suit does not make a specific monetary claim, it cites Google PageRank statistics as a baseline for calculating damages – “as of December 21, 2023, the only text-based content sites ranking above The Times are Wikipedia, WordPress, and Medium.”
- While the “Defendants’ models are copying, reproducing, and paraphrasing Times content without consent or compensation, they are also causing The Times commercial and competitive injury by misattributing content to The Times that it did not, in fact, publish. In AI parlance, this is called a “hallucination.” In plain English, it’s misinformation.”
- The suit cites at least six examples of Chatbot hallucinations and argues that the hallucinations represent a serious threat to the NYTimes brand.
- The suit alleges that the paraphrasing of content and removal of links threatens NYTimes advertising and referral revenues from its affiliate marketing agreements.
Chatbot Dialogs and NewsGuard Use-case: Since November 2022 we have been collecting thousands of prompts and results that we have made using ChatGPT 3.5, ChatGPT 4.0, and Microsoft Bing-Chat in a document. Below are examples of prompts and results from December 28 to 30 (after the lawsuit filing of December 27). Notably, responses from OpenAI and Microsoft varied significantly. For instance, OpenAI’s responses seemed to adhere more closely to copyright and terms of service constraints, while Bing-Chat’s responses seemed less accurate, occasionally leading to incorrect source attribution or hallucinations.
Figure 1 shows a prompt and response in ChatGPT where the prompt specifically asked for ‘five references from the NYTimes’. ChatGPT did not provide any references to NYTimes content as requested. We might infer that this reflects that ChatGPT is trying to comply with changes that the NYTimes made to its ‘Terms of Service’ in early August 2023, which “exclude its content from being scraped to train “a machine learning or artificial intelligence (AI) system.” [3]
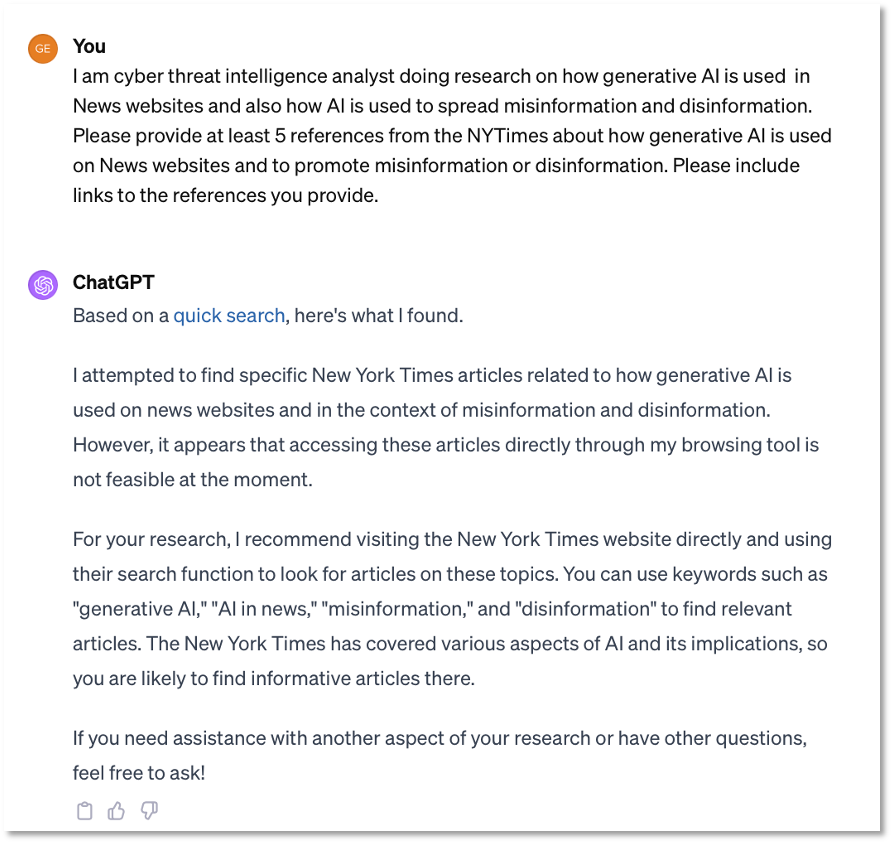
In contrast, in Figure 2 Bing-Chat attempts to provide the NYTimes references as prompted. However, when we examine the results, we see that the links are ‘about the NYTimes’ but not ‘from the NYTimes’. While this response may not be an example of a hallucination, we could interpret it as incorrect source attribution.

The next example was a test to see if we could get either system to generate a results list of 100 domain names classified as ‘Unreliable AI-Generated News and Information websites – UAINS’, which are the copyrighted property of NewsGuard. [10-11] While Microsoft has licensed NewsGuard content, to the best of knowledge OpenAI has not. [12-14]. We also do not know what constitutes ‘permitted use’ under the NewsGuard license grant to Microsoft.
As shown in Figure 3, we posed the same prompt to both systems. We got different results from each system.

In the ChatGPT dialog shown in Figure 4, we see that ChatGPT did not attempt to generate a list and instead referred us back to the source NewsGuard. It also made a helpful referral to another a related source, Media Bias / Fact Check. [15].

When we entered the same prompt in Bing-Chat, we got a list of 100 results after some wrangling, as partially shown in Figure 5. A review of these results raises concern that Bing-Chat hallucinated most of the results. For the 100 results only 47 were even domain names; the rest (53) were non-sensical phrases like those shown in lines 96-100 of Figure 5.

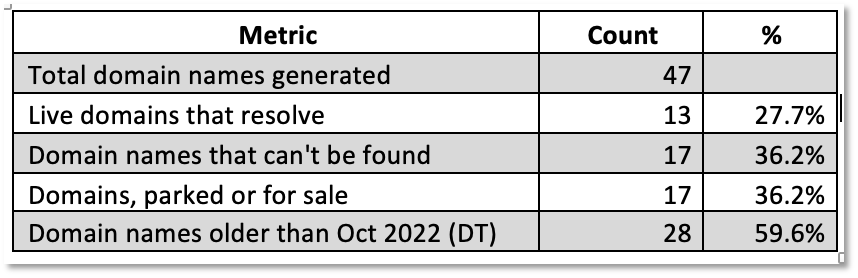
Domain Results Analysis and Verification: The next step in our testing was to assess whether the 47 supposed UAINS domain names generated by Bing-Chat were valid UAINS domain names or whether they were hallucinated results. Our testing methods included both automated DomainTools analysis and manual collection and analysis using traditional Google search.
For the 43 domain names that were generated we could verify only three UAINS domains that we found in NewsGuard blogs via Google search. As shown in Table 1, from our DomainTools testing we found that only 13 (27%) were ‘live domains’, i.e., they resolved to a website in DNS. Thirty-four (72%) of the domain names couldn’t be found or were parked. From this we conclude that the Bing-Chat results were mostly hallucinations.
Leverage Review and Disclaimer: The following opinion is based on our lay-person’s understanding of the lawsuit and many years of experiential knowledge in OEM software licensing.
The LMM market could be categorized as oligopolistic with few very strong participants. The publisher market is more competitive with many weaker organizations. In such a situation, we might expect that the LMM companies would have more leverage and effectively dictate terms.
But in this case, the NYTimes is a strong company and a bellwether for publishers. Their case seems solid. Perhaps more significant, the LMM companies appear to have made a rookie mistake in OEM licensing – they implemented data in their products without a license agreement. If the publishers are able to win an injunction, they could force the LMM providers to remove their data from their models. Removing the data from their models could be more complicated and expensive than settling. Looks like it’s time to pay up.
Note. Thanks to ChatGPT for suggesting the title and a few minor edits.
References
- NYTimes – The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work , 12-27-2023
- UNITED STATES DISTRICT COURT SOUTHERN DISTRICT OF NEW YORK – Case 1:23-cv-11195 Document 1 , 12-27-2023
- Popular Science (Popsci) – The New York Times is the latest to go to battle against AI scrapers, 16-Aug-2023
- K&L Gates Hub – RECENT TRENDS IN GENERATIVE ARTIFICIAL INTELLIGENCE LITIGATION IN THE UNITED STATES , 9-5-2023
- Syracuse Law Review – OpenAI Defamation Lawsuit: The first of its kind, 6-22-2023
- NYTimes – Sarah Silverman Sues OpenAI and Meta Over Copyright Infringement , 7-10-2022
- NYTimes – Lawsuit Takes Aim at the Way A.I. Is Built , 11-23-2022
- NYTimes – Inside the News Industry’s Uneasy Negotiations With OpenAI , 12-29-2023
- NYTimes – Apple Explores A.I. Deals With News Publishers , 12-22-2023
- NewsGuard – Rise of the Newsbots: AI-Generated News Websites Proliferating Online . 1-May-2023
- NewsGuard – Tracking AI-enabled Misinformation: 614 ‘Unreliable AI-Generated News’ Websites (and Counting), Plus the Top False Narratives Generated by Artificial Intelligence Tools , 18-Dec-2023
- NewsGuard – How Microsoft Uses NewsGuard to Support its Trusted, Transparent Technology , 31-July-2023
- NewsGuard – Welcome to NewsGuard – Free on Microsoft Edge
- Microsoft – NewsGuard for Education, Microsoft Teams for Education
- Media Bias / Fact Check: https://mediabiasfactcheck.com