If you’ve been in the IT and cybersecurity business as long as I have, you may feel like a historian, a crank, or both. Hot technologies and companies come and go, but hype is a constant. Through the evolution and disruption, a few innovations define eras – the PC, the Web, the iPhone, and now Generative AI. For each era, history offers valuable lessons and sometimes rhymes. In this post, we’ll share insights from manually testing three general-purpose chatbots – ChatGPT 4.0, Copilot, and Perplexity.ai. We’ll explain how this experience evoked echoes of the evolution of search, directories, enterprise search, metasearch, and NLP-enabled products in the 90s, and how this pattern could play out again for chatbots.
Summary
Since their commercial debut in late 2022, chatbots have emerged as a significant enhancement to, or even an alternative to, traditional search methods. But this promise is tempered by their tendency to produce erroneous or “hallucinated” responses, raising reliability concerns and requiring human verification. Dozens of chatbots are now available, with each offering unique features and varying performance levels. And yet, accuracy and user trust challenges persist. To address these stubborn challenges, strategies such as employing multiple chatbots for consensus results or providing reference links to facilitate user verification hold promise. Over the past month, my personal testing of three popular general-purpose chatbots—ChatGPT 4.0, Copilot, and Perplexity.ai— has revealed subtle distinctions among them. Notwithstanding the subjectivity of the test questions and the small sample set, my personal preference favors Perplexity.ai for its consistent accuracy, ease of results verification through linked sources, and its straightforward and concise responses. Our market research of enterprise and embedded Generative AI implementation also validates the concept of seeking consensus from multiple chatbots to improve reliability and advances it by using software agents and APIs to automate the management of multiple chatbots.
Background
The signals that generative AI is now mainstream are clear. In the past week we saw five AI-themed ads from Microsoft, Google, CrowdStrike, Etsy and Universal Pictures during the Super Bowl [1]. VentureBeat predicted widespread integration of generative AI across all sectors in 2024, [2] while Forbes observed that as generative AI gets embedded in more applications it is ‘getting boring’. [3] And in chatbots, the most common way that users experience generative AI, we’re seeing competing claims of ‘which chatbot is best’ [4] and numerous chatbot comparison reviews in the media. [5-8] The headlines from Forbes and Fortune in Figure 1 illustrate the popular narratives.
To me, claims about chatbot superiority are misguided and mostly hype. We know chatbots often make things up and cannot be relied upon for accuracy. At this early stage of maturity, when there are multiple free or low cost options available for general use, why not try to harness the power of multiple chatbots to get consensus answers? This could increase user confidence. And with Pew Research reporting 52 percent of Americans are “more concerned than excited about the growth of AI” [1], boosting user confidence could accelerate adoption.
As I have been using multiple chatbots in my cyber threat and security research, this seemed like a good research topic. In this post we’ll describe our approach for a simple multi-chatbot collection and testing, and discuss preliminary findings and possible directions for further investigation. It’s important to note that our approach is manual, and while instructive, is cumbersome and does not scale. In enterprise solutions, companies like Sierra are already automating this process, using APIs and software agents to manage chatbot outputs, with the goal of lowering inaccuracies and boosting reliability. [16]
Approach
Our methodology encompassed the following:
- Test Environment Specification: For our analysis we used three leading general purpose chatbots – ChatGPT 4.0, Copilot, and Perplexity.ai.
- Collection Building: We posed thirteen questions to each chatbot, capturing their responses in a structured format. These questions ranged from the simple to the complex and were designed to represent the inquiries of cyber threat intelligence analysts with varying levels of expertise and specialization, from basic tactical information requests to more complex, strategic intelligence queries.
- Use-case Domain: Our model user profile was a cyber threat intelligence analyst with an interest in chatbots, encompassing both simple and complex questions pertaining to terminology, attacks, methodologies, and technologies.
- Metrics Assessment: We evaluated each response based on word count, the number of references and links provided, consistency across chatbots, and the presence of incorrect or questionable content. A senior analyst subjectively assessed the reasonableness and accuracy of answers, without extensive verification of each response.
This approach aimed to balance thoroughness with feasibility, acknowledging the inherent subjectivity in evaluating AI-generated content.
Findings
Qualitative Findings:
- We found that the performance among chatbots was similar and that one was not significantly better than the others. While Copilot’s answers were in outline form, ChatGPT and Perplexity.ai were in narrative form. All could generate tables if requested.
- ChatGPT was the most verbose and had the fewest supporting links.
- Copilot was the most concise and had the most supporting links. We particularly liked the happy face emoji at the end of most answers! 😊
- For the 13 prompts, we preferred Perplexity.ai results for 8 (62%), ChatGPT for 4 (31%), and Copilot for 1 (8%). This preference is based on narrative conciseness and clarity, the supporting references and links, reasonable of the answers, and consistency with the other chatbots.
- The Copilot and ChatGPT answers to question 10 on Volt Typhoon motivation were evaluated as not accurate. See Figures 2-4. We also found that the Copilot answer on cybersecurity chatbots (question 9) was irrelevant.
- We noted inconsistencies among the chatbots. ChatGPT provided contradictory answers related to two questions on port scanning indicator types and classification. Copilot provided contradictory answers to the question on LLM (Large Language Models) and SLMs (Small Language Models. All of the chatbots had different but reasonable answers to question 13 (Spellcheckers).
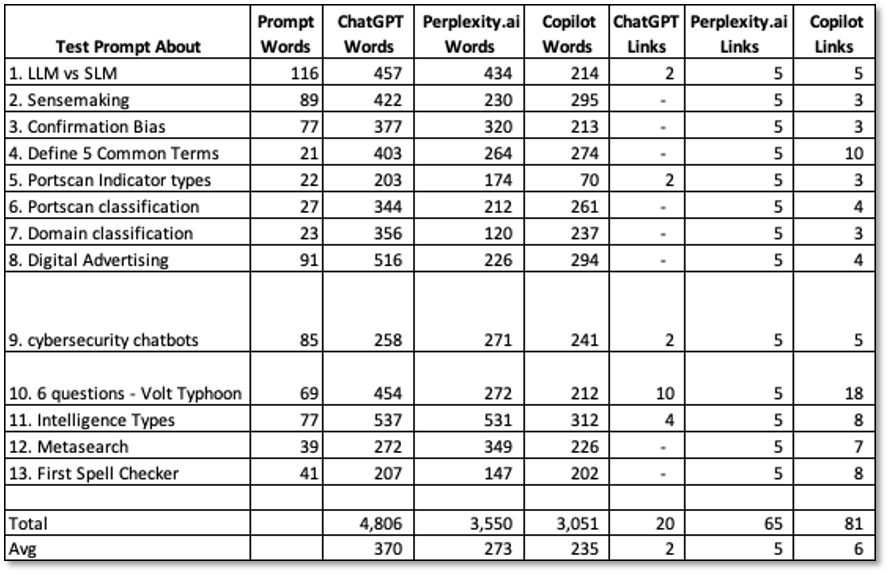
A statistical summary of findings is shown in Table 1. Notes:
- Prompt complexity – Complexity may be a function of number of factors, including number and type of questions, and the number of words in the prompt. All of the prompts had multiple questions.
- Prompt Words – Function of ‘prompt complexity’ (column 2). Generally, the more words, the more complex.
- Results length – Function of the number words in the answer for each chatbot (columns 3-5). ChatGPT answers were 35% more verbose than Perplexity.ai and 48% more verbose than Copilot.
- Reference links – Links help the user verify results. ChatGPT had the fewest references making it hardest to verify. Copilot had the most. Perplexity.ai listed 5 references for every answer.
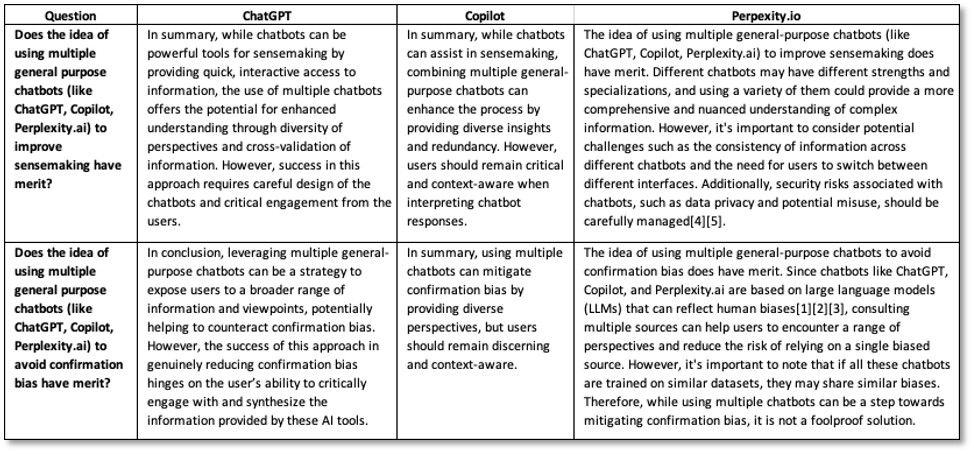
Selected and partial examples for two questions are shown in Table 2. Notes:
- All chatbots agree that using multiple chatbots helps analyst sensemaking.
- All chatbots agree that using multiple chatbots helps analysts avoid confirmation bias.
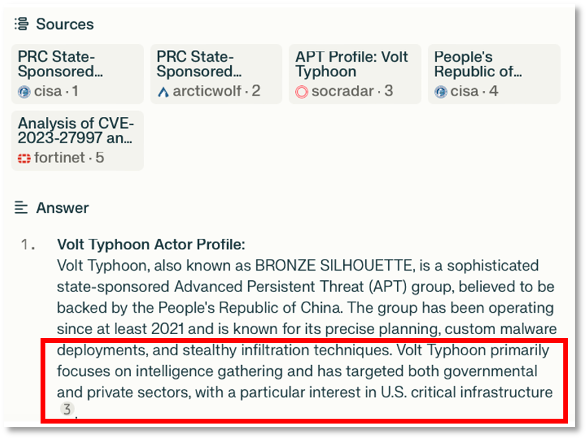
On 13-Feb-2025, I posed the following prompt to the three chabots: “For the cyber threat actor known as Volt Typhoon, please answer 6 questions: 1) Volt Typhoon actor profile, 2) references and links to reports providing Volt Typhoon indicators of compromise (IOCs), 3) references and links reporting specific victim organizations, 4) Date of first (oldest) reports on Volt Typhoon, 5) Date of most recent (newest) report as of 13-Feb-2024, 6) a list of CVEs and products targeted by Volt Typhoon.”
As a challenge test, I was specifically interested in what the results would be for Actor Profile, and what they would say regarding actor motivation. While Chinese threat actors such as Volt Typhoon are known to be motivated by espionage, in the most recent authoritative reporting of Volt Typhoon activity, CISA noted: “Volt Typhoon’s choice of targets and pattern of behavior is not consistent with traditional cyber espionage or intelligence gathering operations, and the U.S. authoring agencies assess with high confidence that Volt Typhoon actors are pre-positioning themselves on IT networks to enable lateral movement to OT assets to disrupt functions.” [17]
As shown in Figure 2 and 3, Copilot and ChatGPT both listed espionage as a motivation. This is not consistent with the most recent guidance from CISA. In Figure 4, note that Perplexity.ai did not assert that espionage was a motivation, though it did assert information gathering which is not consistent with CISA’s guidance.


Outlook
While our focus has been on general-purpose chatbots, we also note the significant development activity in domain-specific generative AI solutions across sectors like finance, travel, retail, and education, and business functions including customer service and HR.
We’re particularly interested in domain-specific solutions for cybersecurity as announced by Microsoft, CrowdStrike, Trend Micro, Flashpoint and others. [8-11] With nation-state and adversarial use of generative AI escalating, [12] we anticipate a surge in the development of domain-specific AI solutions for cybersecurity.
As we look forward to progress in Generative AI, we’re also reminded of how search and NLP tools evolved. [13-15] In the beginning there were many large search and directory platforms (AltaVista, Lycos, Yahoo!, InfoSeek, Excite) and enterprise search platforms (Verity, Autonomy, OpenText). And in NLP (Natural Language Processing), an early ‘task-specific’ application of AI, there were end-user spelling and grammar checkers and dictionaries, machine translation, text processing products for search, text classification, entity extraction, and sentiment analysis. [18] Eventually the early products and tools get subsumed by the platform providers (Microsoft, Google) or open source solutions. The survivors find success by serving specific domains, industries, or functional sectors as solution providers. This ‘creative destruction’ is a familiar pattern we could see again in Generative AI.
Thanks for reading. We welcome your comments.
Final Note. Credit to ChatGPT for its editorial assistance.
References
- CNBC – The way AI will be sold to a skeptical public is starting to become clear , 13-Feb-2024
- VentureBeat – Year of the dragon: We have entered the AI age , 10-Feb-2024
- Forbes – AI Is Getting Boring, And That’s Pretty Exciting , 9-Feb-2024
- Fortune – Google banishes Bard chatbot for AI rebrand as Gemini while Sundar Pichai and Satya Nadella each insist theirs is best , 8-Feb-2024
- Wired – ChatGPT vs. Gemini: Which AI Chatbot Subscription Is Right for You?. , 15-Feb-2024
- Wikipedia – Comparison of user features of chatbots , 13-Feb-2024
- Software Testing Help – Top 12 Best AI Chatbots For 2024 [Review & Comparison] , 8-Feb-2024
- Microsoft Security Copilot – Give security teams an edge with Microsoft Security Copilot
- CrowdStrike – Introducing Charlotte AI, CrowdStrike’s Generative AI Security Analyst: Ushering in the Future of AI-Powered Cybersecurity , 30-May-2023
- Trend Micro – Your New AI Assistant: Trend Vision One™ – Companion ,15- June -2023
- Flashpoint.io – Introducing Ignite AI: Conversational Intelligence for Security Teams , 19-Sept-2023
- Microsoft – Navigating cyberthreats and strengthening defenses in the era of AI , February 2024
- Wikipedia – Metasearch engine
- Wikipedia – Enterprise Search
- QueryAI – Federated Search for Security , 2023
- Wired – This Company Says Conversational AI Will Kill Apps and Websites , 16-Feb-2024
- CISA: Cyber Advisory, Alert Code AA24-038A – PRC State-Sponsored Actors Compromise and Maintain Persistent Access to U.S. Critical Infrastructure , 7-Feb-2024
- Forbes – Is Generative AI Overshadowing The Proven Workhorses Of Modern Tech? , 12-Feb-2024