This is the first in a series of posts describing preliminary research into lexical patterns of Newly Registered Domains (NRDs) pertaining to the Covid-19 pandemic. For our corpus, we used the DomainTools Covid-19 Threat List, a listing of more than 64,000 domain names registered between 1-Jan and 24-March that DomainTools classifies as a ‘threat’. For our NLP (Natural Language Processing) approach, we used a probabilistic segmentation algorithm using n-gram frequencies of English lexemes, developed by my former colleague and fellow Crank – Win Carus, Founder and President of Information Extraction Systems.
Background: The torrent of Covid-19 NRDs has left us with a flood of warnings about the Covid-19 cyber storm. For an authoritative and comprehensive summary, see the 8-April Joint Alert published by the US DHS CISA (Cybersecurity and Infrastructure Security Agency) and the UK’s NCSC (National Cyber Security Centre).
In response to this crisis, the cyber threat intelligence community has mobilized with a range of innovative initiatives. Here’s a sampling:
- NRD Monitoring: The practice of deriving threat feeds from Newly Registered Domains has been used by brand security and network security service providers for close to ten years. Palo Alto Networks pre-Coronavirus (20-Aug-2019) reporting provides a good overview on NRD. On average NRD monitoring systems process about 200,000 NRDs every day. As 70% of NRDs are considered untrustworthy, Palo Alto recommends blocking or closely monitoring NRDs in enterprise traffic.
- In addition to DomainTools, other Cyber Threat Intelligence Service Providers including RiskIQ and LookingGlass Cyber Solutions are also sharing Covid-19 NRD indicators. (full disclosure: LookingGlass is my employer)
- Microsoft reports seeing 60,000 Covid-19 related malicious attachments or URLs and high activity from Trickbot and Emotet malware families. A range of threat actors, from cybercriminals to nation-state actors, have been observed targeting healthcare organizations using COVID-19-themed lures in their campaigns.
- Threat Sharing Cooperatives such as the COVID-19 Cyber Threat Coalition, Gary Warner and CAUCE – Coalition Against Unsolicited Commercial Email, and the Cyber Threat Alliance (CTA) are also providing intelligence reports and indicator sharing.
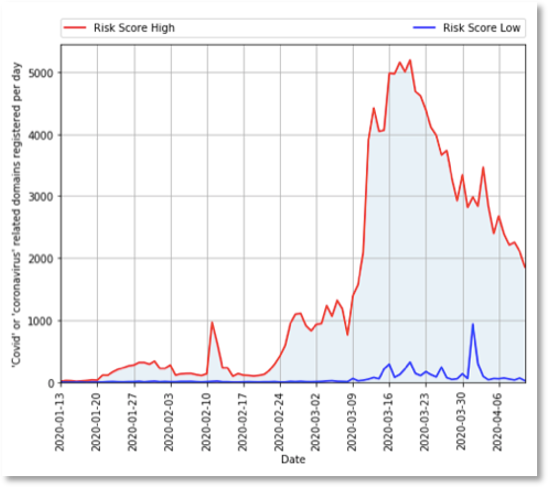
DomainTools Corpus: The DomainTools Threat List corpus contains 64,050 records of domains registered between 1-Jan and 24-March 2020 with a DomainTools risk score of 70 or greater. The domains were matched by terms related to Covid-19, Coronavirus and other lexically and semantically relevant terms. We downloaded a CSV containing three attributes in a single field: domain name, date created, and risk score. A trend-line of domain registrations over time is provided by DomainTools via the COVID-19 Cyber Threat Coalition (referenced above). As shown, the high domain registrations spiked on 9-March.
Inside the Data: After preparing the data we went through several parsing cycles, refining the parser after each iteration. An unusual feature of the corpus is the relatively long length of the source strings (domain name stripped of the gTLD or ccTLD). Source strings of 25 characters are common. Some are greater than 50 characters with 12 distinct lexemes or word-like component strings.
After several processing cycles we ended up with an analytical data set with 6,648 unique lexemes with frequency values and rankings. Once we prepared the analytic data set, we performed an analyst review using our knowledge of the threat domain. The goal was to identify lexical patterns in the data that we could use to prioritize further research.
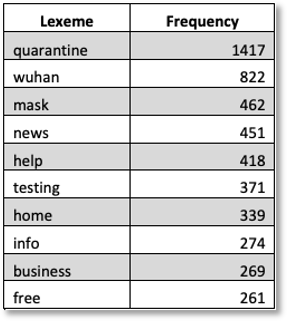
For our first pass, our objective was to identify terms that might have high discriminatory or predictive value for further analysis. Table 1 shows frequency rankings for selected lexemes or terms. Key lexemes – corona, coronavirus, covid – were excluded from this set.
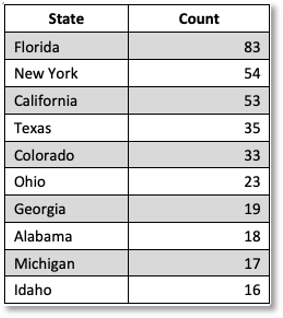
To direct and narrow our research, we picked a use-case where our objective was to understand which US States had the highest representation in the corpus. Table 2 shows a top-10 frequency ranking by State.
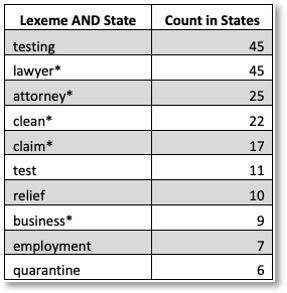
For our last example, we wanted to join states by high-value terms. This is shown in Table 3. Note: * represents wild-card permutation of the term base-form.
Direction: Cyber threat actors and scammers often register domain names in bulk with the intent to use them in campaigns. Suspicious domain names tend to be longer than reputable domains. By analyzing lexeme permutations and ordering, it is possible to more quickly identify illicit campaigns. Based on this preliminary work we believe that further development of domain lexeme parsing could help cyber threat researchers, law enforcement and domain registrars more quickly spot malicious or disreputable domain registrations practices and shut down campaigns more quickly. We will provide an example of this in our next post.